A few months ago, Radare2 (aka r2), an open source disassembler which can be entirely used by command line, started implementing AI plugins to assist with artificial intelligence.
Assuming you don’t have any API key for a paid language model, I’m going to explain how to set up r2 with a free local AI model. We’ll also discuss the results.
Setup
We need:
- A fresh radare2 (I’m not covering this) and an updated package manager:
r2pm -U - Decai. That’s a decompiler based on AI. To install it,
r2pm -ci decai. - A language model. As I don’t have access to any commercial AI, I’ll use a local language model. I am not sure what’s the intended way to download a language model, but I do it via a dummy request to r2ai. So, we need r2ai, to be installed with
r2pm -ci r2ai. - To use a local model, we need r2ai-server:
r2pm -ci r2ai-server.
Installing a language model
I launch r2ai interactively with r2pm -r r2ai. This should give you a r2ai prompt:
$ r2pm -r r2ai
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
[r2ai:0x00006aa0]>The available commands can be listed with -h. Language models often have funky long names. Use -M to get examples of local models (see the “decai” section) , and select the model I want to use with -m.
[r2ai:0x00006aa0]> -M
Decai:
-m ibm-granite/granite-20b-code-instruct-8k-GGUF
-m QuantFactory/granite-8b-code-instruct-4k-GGUF
-m cognitivecomputations/dolphin-2.9.3-mistral-nemo-12b-gguf
-m bartowski/Gemma-2-9B-It-SPPO-Iter3-GGUF
[r2ai:0x00006aa0]> -m QuantFactory/granite-8b-code-instruct-4k-GGUF
[r2ai:0x00006aa0]> write a 4 line poem thanking Pancake, the maintainer of radare2, for his time and workTo initiate the download of the model, I’m not sure what’s the official way to do it. Personally, I simply ask the AI a dummy questions, e.g. write a short poem, or whatever. This triggers several questions about which exact model r2ai should download. For this attempt, I selected the smallest model.
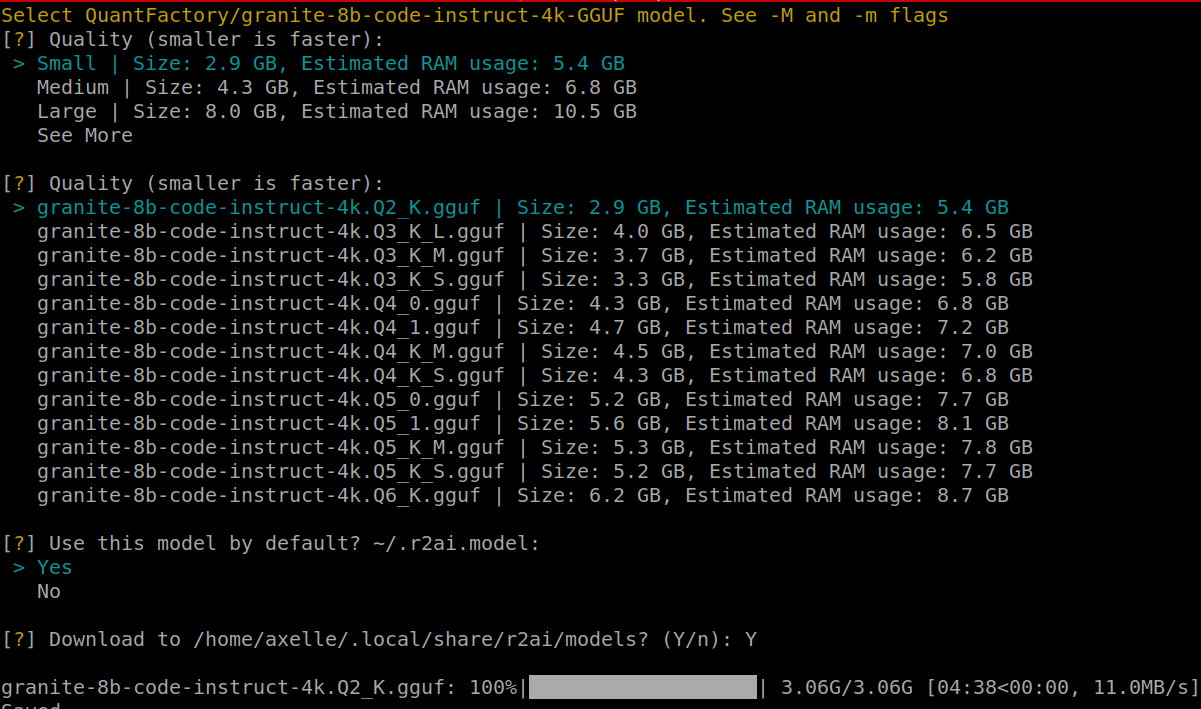
Launching r2ai-server
Next step is to make that model available. For that I use r2ai-server.
$ r2pm -r r2ai-server -l
r2ai
llamafile
llamacpp
koboldcpp
$ r2pm -r r2ai-server -m
granite-8b-code-instruct-4k.Q2_KOption -m select the model, and -l the server. Note the server launches on port 8080 by default (configurable with -p).
$ r2pm -r r2ai-server -l r2ai -m granite-8b-code-instruct-4k.Q2_K
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
[09/17/24 14:50:24] INFO r2ai.server - INFO - [R2AI] Serving at port 8080 web.py:334Testing with Caesar encryption
Let’s test the AI-assisted decompiler. I wrote a very basic routine, which implements the ancient Caesar encryption algorithm, and compiled it.
int shift = 3;
char *encrypt(char *input, int len) {
char *output = (char*) malloc(sizeof(char)*(len+1));
for (int i = 0; i < len; i++) {
output[i] = (input[i] + shift) % 256;
}
output[len] = '\0';
return output;
}I run r2, analyze the program (aaa), list functions (afl) to locate encrypt(), jump to the function (s sym.encrypt), disassemble it to have a look (pdf).
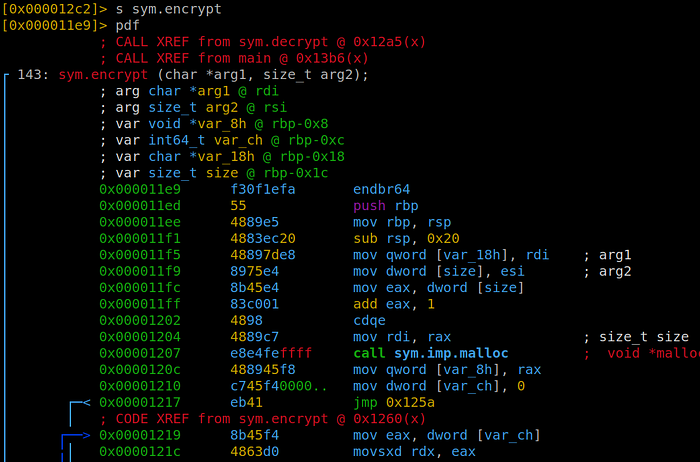
Using decai
Let’s get some help from the AI to understand the assembly. The command is decai, followed by an option: -H for help, -d to decompile the current function, -e to configure.
In my case, all default settings are correct, except the api which should be set to r2ai: decai -e api=r2ai. Some other settings can be set like decai -e debug=true for more information, or decai -e lang=java to produce Java output (depending on models and complexity of the function, some output languages may work better than others).
Finally, issue decai -d to ask the AI to help us understand the current function. Note that the answer may take a long time to return (depends on your machine, the model, the question…) and unfortunately there is no progress bar for that.
We can check the r2ai-server receives the request (at 14:50:53). Actually, decai posts an HTTP request (on port 8080), via curl, asking it to “show the code with no explanation” etc.
GET
CUSTOM
RUNLINE: -R
127.0.0.1 - - [17/Sep/2024 14:50:53] "GET /cmd/-R HTTP/1.1" 200 -
GET
CUSTOM
RUNLINE: -i /tmp/.pdc.txt Only show the code with no explanation or introductions. Simplify the code: - take function arguments from comment - remove dead assignments - refactor goto with for/if/while - use better names for variables - simplify as much as possible. Explain this pseudocode in javaAt 14:51:41, I got the following response:
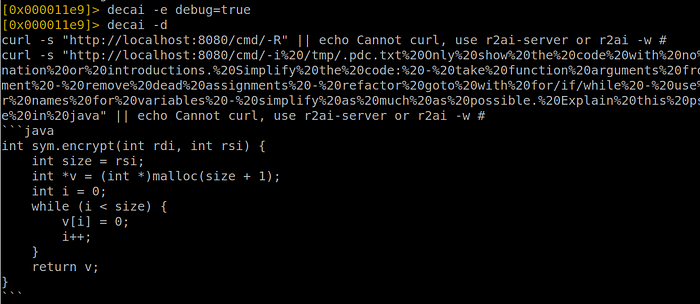
How good is that result, compared to the original source code? The AI understood the function takes 2 arguments, how the malloc is done, and the loop. But it completely missed the most important part: what’s done inside the loop i.e shifting character by 3.
Decompiling the main
Our first test is a bit disappointing in quality, but let’s not jump to a conclusion yet. This time, I asked it to decompile the main() function.
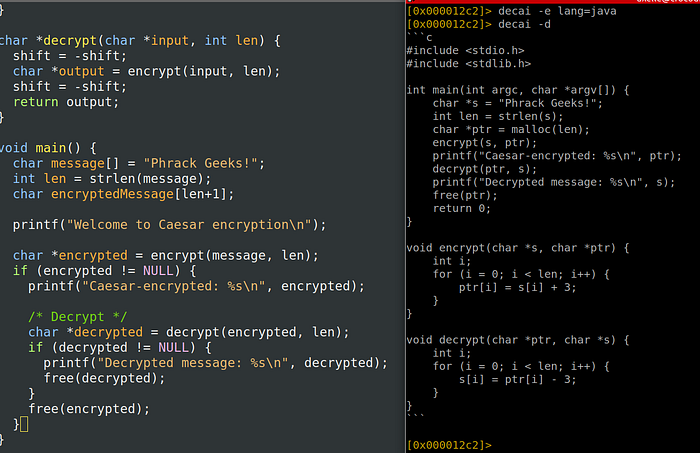
The result is far better!
- The login of
main()is correctly implemented. Only the printf “Welcome to Caesar encryption” is missing (this is surprising), and the tests for null pointer (not very important to understand the logic). - The logic of
encrypt()anddecrypt()are perfectly correct this time! It’s just surprising the AI does not work out the return type.
Overall, this time, I’d say that because the logic is well implemented, the results are helpful to a reverse engineer. Of course, we’ll still need some brains to work out the initial source code, but we’re one step closer.
Decompiling Dart
In a final test, I ask decai to decompile the same Caesar program, implemented in Dart. I compiled it as a non-stripped AOT binary, and asked decai to provide the decompilation in pseudo Dart.
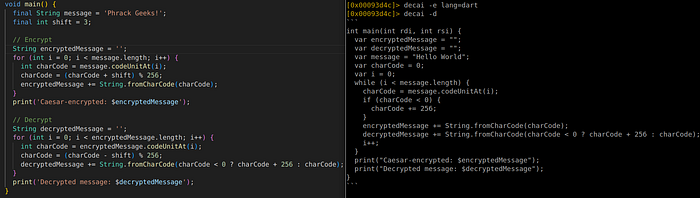
The result is “amusing” but not satisfactory: it invents a “Hello World” string which never existed (this is typical of AI errors), and doesn’t grasp the Caesar algorithm.
Finally, I tested decai over a stripped Dart AOT binary. The AI server did not respond (“input is too large”).
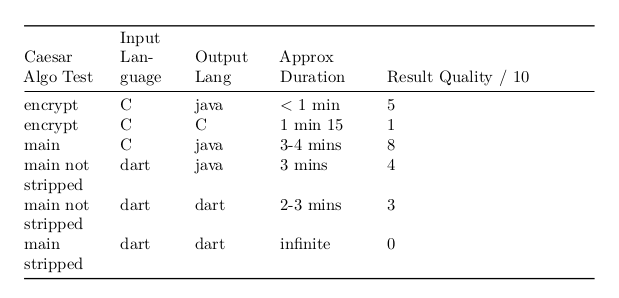
Conclusion
- Decai can be used with a local AI model.
- Over a (very) simple program, the quality of results are quite useful, but for more complex cases, currently, the AI simply never responds (“infinite” loop) or produces useless results.
- It’s obvious, but it should be repeated: the quality of results depends on the AI model: pancake obtains excellent results with Claude AI, proof that decai is able to work perfectly well when fed with a good model! [haskell, bash, C].
Many thanks to pancake, and all people who contribute to r2ai, r2ai-server and decai! Love the idea!
— Cryptax
